UNIDAD VIII
INTELIGENCIA ARTIFICIAL Y SISTEMAS EXPERTOS

-DEFINICIÓN DE INTELIGENCIA ARTIFICIAL Y SISTEMAS EXPERTOS
-PERSPECTIVAS DE LA INTELIGENCIA ARTIFICIAL
-CARACTERÍSTICAS DE LOS EXPERTOS
-APLICACIONES DE LOS SISTEMAS EXPERTOS EN LOS NEGOCIOS
-VENTAJAS Y LÍMITES DE LOS SISTEMAS EXPERTOS
-HERRAMIENTAS DE LOS SISTEMAS EXPERTOS: PROLOG Y LISP
-LENGUAJES DE CUARTA GENERACIÓN
-FUTURO DE LOS SISTEMAS DE INFORMACIÓN
DEFINICIÓN DE SISTEMA ARTIFICIAL Y SISTEMAS EXPERTOS.
La inteligencia artificial es un campo de estudio que busca explicar y emular inteligencia, desarrollándola en términos de procesos computacionales que, si son utilizados correctamente por un programa, éste puede exhibir un comportamiento inteligente. Esto es, la inteligencia artificial expresa la pretensión de modelar, por medio de máquinas computadoras, la inteligencia del ser humano. Esta pretensión se basa en la experiencia que la humanidad ha acumulado en el campo de la elaboración de modelos para interpretar la naturaleza y el comportamiento de la fracción del Universo con la cual tiene contacto.
Para poder modelar un sistema, el creador del modelo deberá contar con herramientas útiles para representar tanto la forma como el comportamiento del sistema, de tal manera que otros seres humanos puedan comprender el sistema a través del modelo creado.
La Inteligencia artificial es el campo científico de la informática que se centra en la creación de programas y mecanismos que pueden mostrar comportamientos considerados inteligentes. En otras palabras, la IA es el concepto según el cual “las máquinas piensan como seres humanos”.
Normalmente, un sistema de IA es capaz de analizar datos en grandes cantidades (big data), identificar patrones y tendencias y, por lo tanto, formular predicciones de forma automática, con rapidez y precisión. Para nosotros, lo importante es que la IA permite que nuestras experiencias cotidianas sean más inteligentes. ¿Cómo? Al integrar análisis predictivos (hablaremos sobre esto más adelante) y otras técnicas de IA en aplicaciones que utilizamos diariamente.
Siri funciona como un asistente personal, ya que utiliza procesamiento de lenguaje natural
Facebook y Google Fotos sugieren el etiquetado y agrupamiento de fotos con base en el reconocimiento de imagen
Amazon ofrece recomendaciones de productos basadas en modelos de canasta de compra
Waze brinda información optimizada de tráfico y navegación en tiempo real.
Con poco más de diez años de antigüedad, la Vida Artificial se ha convertido en un punto de referencia sólido de la ciencia actual.
En septiembre de 1987, 160 científicos en informática, física, biología y otras disciplinas se reunieron en el Laboratorio Nacional de Los Álamos para la primera conferencia internacional sobre Vida Artificial. En aquella conferencia se definieron los principios básicos que han marcado la pauta desde entonces en la investigación de esta disciplina.

Un concepto básico dentro de este campo es el de comportamiento emergente. El comportamiento emergente aparece cuando se puede generar un sistema complejo a partir de reglas sencillas. Para que se dé este comportamiento se requiere que el sistema en cuestión sea iterativo, es decir, que el mismo proceso se repita de forma continua y además que las ecuaciones matemáticas que definen el comportamiento de cada paso sean no lineales.
Por otra parte, un autómata celular consiste en un espacio n-dimensional dividido en un conjunto de celdas, de forma que cada celda puede encontrarse en dos o más estados, dependiendo de un conjunto de reglas que especifican el estado futuro de cada celda en función del estado de las celdas que le rodean.
Hay dos posturas dentro de la Vida Artificial: la fuerte y la débil.
Para los que apoyan la postura débil, sus modelos son solamente representaciones simbólicas de los síntomas biológicos naturales, modelos ciertamente muy útiles para conocer dichos sistemas, pero sin mayores pretensiones.
Para los que defienden la versión fuerte, dicen que se puede crear vida auténtica a partir de un programa de ordenador que reproduzca las características básicas de los seres vivos.
Desde este punto de vista, la vida se divide en vida húmeda, que es lo que todo el mundo conoce como vida, vida seca, formada por autómatas físicamente tangibles, y vida virtual, formada por programas de computador. Las dos últimas categorías son las que integran lo que genéricamente se conoce como Vida Artificial.
Para defender un punto de vista tan radical, los defensores de la postura fuerte, aluden a un conjunto de reglas que comparten las tres categorías anteriores:
La biología de lo posible.
La Vida Artificial no se restringe a la vida húmeda tal como la conocemos, sino que "se ocupa de la vida tal como podría ser". La biología ha de convertirse en la ciencia de todas las formas de vida posibles.
- Método sintético.
La actitud de la Vida Artificial es típicamente sintética, a diferencia de la biología clásica, que ha sido mayoritariamente analítica. Desde este punto de vista, se entiende la vida como un todo integrado, en lugar de desmenuzarlo en sus más mínimas partes.
Vida real (artificial).
La Vida Artificial es tal porque son artificiales sus componentes y son artificiales porque están construidos por el hombre. Sin embargo, el comportamiento de tales sistemas depende de sus propias reglas y en ese sentido es tan genuino como el comportamiento de cualquier sistema biológico natural.
Toda la vida es forma.
La vida es un proceso, y es la forma de este proceso, no la materia, lo que constituye la esencia de la vida. Es absurdo pretender que sólo es vida genuina aquella que está basada en la química del carbono, como es el caso de la vida húmeda.
Construcción de abajo hacia arriba.
La síntesis de la Vida Artificial tiene lugar mejor por medio de un proceso de información por computador llamado programación de abajo hacia arriba. Consiste en partir de unos pocos elementos constitutivos y unas reglas básicas, dejar que el sistema evolucione por sí mismo y que el comportamiento emergente haga el resto. Poco a poco el sistema se organiza espontáneamente y empieza a surgir orden donde antes sólo había caos.
Esta clase de programación contrasta con el principio de programación en la Inteligencia Artificial. En ella se intenta construir máquinas inteligentes hechos desde arriba hacia abajo, es decir, desde el principio se intenta abarcar todas las posibilidades, sin dejar opción a que el sistema improvise.
El principio de procesamiento de información en la Vida Artificial se basa en el paralelismo masivo que ocurre en la vida real. A diferencia de los modelos de Inteligencia Artificial en los que el procesamiento es secuencial, en la Vida Artificial es de tipo paralelo, tal y como ocurre en la mayoría de fenómenos biológicos.
Granja de Evolución.
La evolución en la naturaleza fue la clave para mejorar los organismos y desarrollar la inteligencia. Michael Dyer, investigador de Inteligencia Artificial de la Universidad de California, apostó a las características evolutivas de las redes neuronales (redes de neuronas artificiales que imitan el funcionamiento del cerebro) y diseñó Bio-Land.
Bio-Land es una granja virtual donde vive una población de criaturas basadas en redes neuronales.
Los biots pueden usar sus sentidos de la vista, el oído e incluso el olfato y tacto para encontrar comida y localizar parejas. Los biots cazan en manadas, traen comida a su prole y se apiñan buscando calor.
Lo que su creador quiere que hagan es hablar entre ellos, con la esperanza de que desarrollen evolutivamente un lenguaje primitivo.
Los métodos tradicionales en Inteligencia Artificial que permitieron el desarrollo de los primeros sistemas expertos y otras aplicaciones, ha ido de la mano de los avances tecnológicos y las fronteras se han ido expandiendo constantemente cada vez que un logro, considerado imposible en su momento, se vuelve posible gracias a los avances en todo el mundo, generando incluso una nueva mentalidad de trabajo que no reconoce fronteras físicas ni políticas. Se entiende como un esfuerzo común.
La comprensión de los mecanismos del intelecto, la cognición y la creación de artefactos inteligentes, se vuelve cada vez más una meta que sueño, a la luz de los enormes logros, tan sólo en alrededor de medio siglo de desarrollo de las ciencias de la computación y de poner la lógica al servicio de la construcción de sistemas.

Características de la inteligencia artificial:
Origen del término
Si bien la idea de la máquina inteligente nos ha acompañado desde hace mucho, con ejemplos como el Golem o los robots de la Ciencia Ficción, el término “Inteligencia artificial” se empleó por primera vez en 1956, por John McCarthy, eminente computista norteamericano quien contribuyó enormemente a este tipo de estudios.
Concepto
La AI suele abarcar los aspectos racionales y lógicos del pensamiento.
El concepto de la Inteligencia Artificial es todavía difuso. En líneas generales, podría referirse al intento de construir un sistema informático que reproduzca e incluso trascienda las labores de pensamiento del cerebro humano, con su mismo margen de autonomía, individualidad y creatividad, pero sacando provecho a las ventajas del cómputo veloz y masivo de las computadoras.
Este concepto suele abarcar los aspectos racionales y lógicos del pensamiento, pero lo tiene difícil frente a conceptos de otra naturaleza como el amor, el compromiso o la moral.
Escuelas de pensamiento
El estudio de la Inteligencia Artificial abarca dos escuelas distintas:
Inteligencia Artificial simbólico-deductiva. Conocida también como Inteligencia Artificial convencional, intenta comprender y replicar el comportamiento humano desde una perspectiva de análisis formal y estadística.
Inteligencia Artificial subsimbólica-inductiva. También llamada Inteligencia Artificial computacional, persigue el desarrollo y el aprendizaje interactivo, basándose en datos empíricos y en modificaciones de los parámetros de conexión.
Pilares
Se consideran cuatro los pilares del estudio y desarrollo de la Inteligencia Artificial:
La búsqueda de un estado deseado, entre los conjuntos posibles de acuerdo a las acciones ofrecidas en un instante determinado, es decir, la libre elección.
Algoritmos genéticos inspirados en el código genético humano (ADN).
Redes neuronales artificiales, que imitan el funcionamiento de los cerebros orgánicos.
Razonamiento de lógica formal, semejante al pensamiento abstracto de los humanos.
Aplicaciones
Las aplicaciones contemporáneas de la Inteligencia Artificial en sus distintos prototipos y estados de desarrollo, pueden resumirse en:
Videojuegos y software de entretenimiento inteligente.
Soporte digital para servicios online y programas computacionales.
Sistemas de procesamiento masivo de datos e información.
Robótica y sistemas de automatización complejos.
Test de Turing
Un problema de la IA es la dificultad real para distinguir entre un sistema artificial realmente inteligente, y uno programado para darle esa impresión al usuario (fingirlo).
Para ello, el matemático y computista inglés Alan Turing diseñó una prueba, bautizada luego en su honor, que consistía en hacer que una persona leyera una conversación entre otro individuo y un computador programado para imitar en sus respuestas a la inteligencia humana.
Si luego de 5 minutos el observador era incapaz de distinguir la máquina de la persona, el sistema habría superado la prueba.
Historia
El primer trabajo propiamente dicho en el campo de la Inteligencia Artificial es el modelo de neuronas artificiales de Warren McCulloch y Walter Pitts en 1943, si bien este término aún no había sido acuñado.
La llegada de Turing y sus trabajos en el área desde 1950 supondrían la inauguración de una rama computacional que crecería a grandes pasos durante los 60 y 70, con los sistemas expertos de apoyo en la resolución de ecuaciones matemáticas y, posteriormente, con los guiones o “scripts” informáticos.
En 1997 ocurriría un importante hito en materia de Inteligencia Artificial: el ajedrecista Gari Kaspárov perdería frente a Deep Blue, un computador especializado en el juego. Muchos verían en esto el anuncio de las computadoras inteligentes que vendrán.
Temores
SISTEMAS EXPERTOS
DEFINICIÓN DE SISTEMAS EXPERTOS
Bajo el término de sistemas expertos se encuentran un nuevo tipo de software que imita el comportamiento de un experto humano en la solución de un problema. puede almacenar conocimientos de expertos para un campo determinado y solucionar un problema mediante deducción lógica de conclusiones.
VENTAJAS DE SISTEMAS EXPERTOS
Se crearon sistemas expertos que además basándose en algunas de acción (silogismos) y el análisis de posibilidades nos dan una ayuda muy útil, en todas las ramas de la acción humana. De este modo se crearon sistemas expertos para tareas genéricas: es decir para la monitorización y el diagnóstico, además de los trabajos de simulación de la realidad. se está usando en gran medida para la monitorización y diagnóstico: como en plantas de energía, grandes industrias, cohetes, control de tráfico aéreo, búsqueda de yacimientos petrolíferos y hasta hospitales.
DESVENTAJAS DE SISTEMAS EXPERTOS
Tiene sus limitaciones propias, al ser un especialista en tan solo un área, pero un completo idiota en casi todas las otras ramas del pensamiento humano y al ser rule-base-systems (sistemas basados en reglas fijas), donde se pierden algunas veces la creatividad y un sentido común.
CAPACIDADES DE LOS SISTEMAS EXPERTOS
Los siguientes expertos se aplican por norma general en problemas que implican un procedimiento basado en el conocimiento. Un procedimiento de solución basado en el conocimiento comprende las siguientes capacidades.
Utilización de normas o estructuras que contengan conocimiento y experiencias de expertos especializados.
Deducción lógica de conclusiones.
Capaz de interpretar datas ambiguos.
Manipulación de conocimientos afectados por valores de probabilidad
FUNCIÓN DE SISTEMAS EXPERTOS
La función de un sistemas experto es la de aportar soluciones a problemas, como si de humanos se tratara, es decir, capaz de mostrar soluciones inteligentes. Es posible gracias a que al sistema lo crean con expertos (humanos), que intentas estructurar y formalizar conocimientos poniéndolos a disposición del sistema, para que este pueda resolver una función dentro del ámbito del problemas, de igual forma que lo hubiera hecho un experto acceder a los conocimientos adquiridos por experiencia es lo más difícil, ya que los expertos, al igual que otras personas, apenas lo reconocen como tales. Son buscados con mucho esfuerzo y cuidado siendo descubiertos de uno en uno, poco a poco.
COMPONENTES DE UN SISTEMAS EXPERTOS
La base de conocimientos:
La base de conocimientos contiene todos los hechos, las reglas y los procedimientos del dominio de aplicación que son importantes para la solución del problema. Contiene el conocimiento de los hechos y la experiencia de los expertos de un dominio determinado.
Un sistema experto contiene conocimiento de los hechos y de las experiencias de los expertos en un dominio determinado.
El mecanismo de inferencia de un sistema experto puede simular la estrategia de solución de un experto. Es la unidad lógica con la que se extraen conclusiones de la base de conocimiento, según un método fijo de solución de problemas que esta configurado, limitando el procedimiento humano de los expertos para solucionar problemas.
Una conclusión se produce mediante aplicación de las reglas sobre hechos presentes. Las funciones de mecanismo de inferencia son:
1. Determinación de las acciones que tendrá lugar, el orden en que lo harán y cómo lo harán entre las diferentes partes del sistema experto.
2. Determinar cómo y cuándo se procesarán las reglas, y dado el caso también la elección de que reglas deberán procesarse.
3. Control de diálogo con el usuario.
El componente explicativo:
Explica al usuario la estrategia de solución encontrada y el porqué de las decisiones tomas.
Las soluciones descubiertas por los expertos deben poder ser repetibles, tanto por lo el ingeniero del conocimiento en la base de comprobación, así como por usuario. La exactitud de los resultados, sólo podrá ser controlada, naturalmente por los expertos. siempre es deseable que durante el trabajo de desarrollo del sistema se conozca el grado de progreso en el procesamiento del problema.
A pesar de insistir sobre la importancia del componente explicativo es muy difícil y hasta ahora no se han conseguido cumplir todos los requisitos de un buen componente explicativo. Muchos representan el progreso y la consulta al sistema de forma gráfica, además los componentes explicativos intentan ajustar su función rastreando hacia atrás el camino de la solución. aunque encontrar la forma de representar finalmente en un texto lo suficiente inteligible las soluciones encontradas depara las mayores dificultades.
Los componentes explicativos pueden ser suficientes para el ingeniero del conocimiento, ya que está muy familiarizado con el entorno del conocimiento de datos y a veces basta también para el experto, pero para el usuario, que a menudo desconoce las sutilezas del conocimiento de datos, los componentes explicativos son todavía un poco satisfactorios.
La interfaz del usuario:
Sirve para que éste pueda realizar una consulta en un lenguaje lo más natural posible. Este componente es la forma en la que el sistemas se presenta ante el usuario.
Requisitos o características de la interface que se presenta al usuario al desarrollar el sistema.
1. El aprendizaje del manejo debe ser rápido.
2. Debe evitarse en lo posible la entrada de datos erróneos.
3. Los resultados deben presentarse en una forma clara para el usuario.
4. Las preguntas y explicaciones deben ser comprensibles.
El componente de adquisición
Ofrece ayuda a la estructuración e implementación del conocimiento en la base de conocimientos. Un buen componente de adquisición ayudara considerablemente la labor del ingeniero del conocimiento. Este puede concentrarse principalmente en la estructuración del conocimiento sin tener que dedicar tanto tiempo en la actividad de programación. Daremos una reglas o requisitos de nuestro componente de adquisición.
Requisitos o características del componentes de adquisición.
1. El conocimiento, es decir, las reglas, los hechos, las relaciones entre los hechos, debe poder introducirse de la forma más sencilla posible. 2. Posibilidades de representación clara en todas la informaciones contenida en una base de conocimientos. 3. Comprobación automática de la sintaxis. 4. Posibilidad constante de acceso al lenguaje de programación.
CARACTERÍSTICAS
CAPACIDAD DE INFERENCIA DEDUCTIVA:
Esto significa que los agentes no solo deben recuperar la información almacenada en la base de datos, sino hacer deducciones usando información para hacer deducciones que produzcan nuevas informaciones para la base de datos.
CRECIMIENTO DINÁMICO:
Porque los datos y las reglas están sujetas a constante revisión, es decir, es fácil devorar o modificar los datos.
COLECCIÓN INTEGRADA DE CONOCIMIENTO:
Los agentes que constituyen el sistema pueden representar los juicios de muchos expertos en varias partes del globo. Estas experiencias son guardadas en un solo lugar por lo que es posible la utilización luego por los expertos o no expertos también. Sin embargo, la real utilidad de ese sistema es que permite un constante intercambio de datos y juicios de líderes expertos, y esto permite la formación de nuevas reglas e ideas acerca del tema.
PROLOG está orientado a la resolución de problemas mediante el cálculo de predicados, basado en: Preguntas a la base de datos. Pruebas matemáticas. El programa PROLOG especifica cómo debe ser la solución, en vez de dar el algoritmo para su resolución. La solución se obtiene mediante búsqueda aplicando la lógica de predicados. El programa PROLOG se compone de unos hechos (datos) y un conjunto de reglas, es decir, relaciones entre objetos de la base de datos. La ejecución del programa cargado en memoria consiste en realizar una pregunta de forma interactiva: el intérprete generará por inferencia los resultados que se deducen a partir del contenido de la base de datos. PROLOG tiene una sintaxis y semántica simples. Sólo busca relaciones entre los objetos creados, las variables y las listas, que son sus estructuras básicas.

3. LISP Es un lenguaje de programación aplicativo o funcional, de propósito general, se basa en la aplicación de funciones a los datos y se apoya en la utilización de funciones matemáticas para el control de los mismos. El elemento fundamental en el LISP es la lista, más ampliamente el término. Cada función del LISP y cada programa que generemos con él vienen dado en forma de lista. . El nombre proviene del término “List Processing ”.LISP es muy utilizado en la Inteligencia Artificial. El LISP trata a los elementos o paramentos que le introducimos de manera no destructiva, de forma que la mayoría de las funciones nos devuelven una lista que es el resultado de alguna transformación de otra que recibió, pero sin cambiar a esta (la que recibió). Una de las razones por las que el LISP esta especialmente dotado para la programación en inteligencia artificial (IA), es precisamente, porque su código y todos los datos tienen la misma estructura, en forma de lista.
4. CLIPS Representación del Conocimiento: CLIPS permite manejar una amplia variedad de conocimiento, soportando tres paradigmas de programación: el declarativo, el imperativo, y el orientado a objetos. Portabilidad: CLIPS fue escrito en C con el fin de hacerlo más portable y rápido, y ha sido instalado en diversos sistemas operativos (Windows 95/98/NT, Mac OS X, Unix) sin ser necesario modificar su código fuente. CLIPS puede ser ejecutado en cualquier sistema con un compilador ANSI de C, o un compilador de C++. El código fuente de CLIPS puede ser modificado en caso que el usuario lo considere necesario, con el fin de agregar o quitar funcionalidades. Integralidad: CLIPS puede ser embebido en código imperativo, invocado como una sub-rutina, e integrado con lenguajes como C, Java, FORTRAN y otros. Desarrollo Interactivo: La versión estándar de CLIPS provee un ambiente de desarrollo interactivo y basado en texto; este incluye herramientas para la depuración, ayuda en línea, y un editor integrado. Verificación/Validación: CLIPS contiene funcionalidades que permiten verificar las reglas incluidas en el sistema experto que está siendo desarrollado, incluyendo diseño modular y particionamiento de la base de conocimientos del sistema, chequeo de restricciones estático y dinámico para funciones y algunos tipos de datos, y análisis semántico de reglas para prevenir posibles inconsistencias.
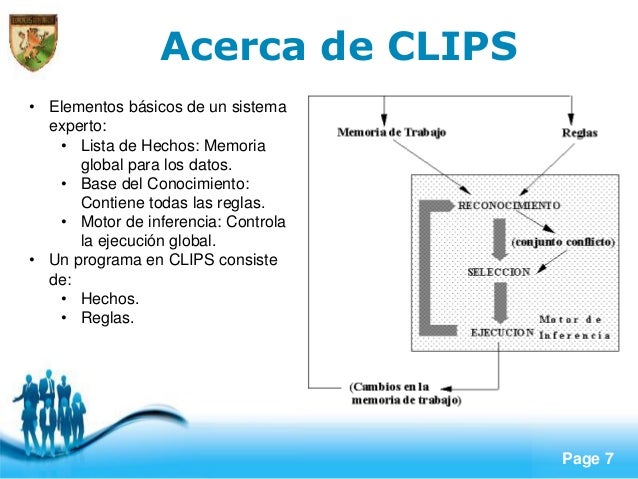
5. Cuadro Comparativo 1/2 PROLOG LISP CLIPS Herramienta para programar artefactos electrónicos mediante el paradigma lógico. Herramienta para programar Herramienta de desarrollo y desarrollar programas manejo de sistemas expertos. relacionados con la inteligencia artificial. Prolog está basado en la lógica de primer orden, es aquella que resuelve problemas formulados con una serie de objetos y relaciones entre ellos. Es uno de los primeros CLIPS fue escrito en C con el lenguajes de alto nivel y junto fin de hacerlo más portable y con Prolog el lenguaje rápido. simbólico más usado en Lenguaje Artificial Ideado a principios de los Fue desarrollado en 1954 por Fue creado a partir de 1984, años 70 en la Universidad de John McCarthy en el Lyndon B. Johnson Aix-Marseille Space de la NASA. Proveniente del francés El nombre LISP deriva del CLIPS es un acrónimo de C PROgrammation en LOGique "LISt Processing" (Proceso de Language Integrated Production System (Sistema LIStas) de Producción Integrado en Lenguaje C)
6. Cuadro Comparativo 2/2 PROLOG LISP Se compone de hechos (datos) Se compone de listas y un conjunto de reglas, es encadenadas y por un conjunto decir, relaciones entre objetos de instrucciones o reglas. de la base de datos. Los comentarios se definen Los comentarios se definen con entre los símbolos /* y */. el símbolo “;” (punto y coma) CLIPS Se compone básicamente de reglas definidas, y está basado en texto que incluyen herramientas. Los comentarios se colocan detrás de un punto y coma (;). Una llamada concreta a un predicado o a una determinada función, con unos argumentos concretos, se denomina objetivo. Una llamada de función o una forma sintáctica es escrita como una lista, con la función o el nombre del operador en primer lugar, y los argumentos a continuación. Una función comienzan con un paréntesis izquierdo, seguido por el nombre de la función y a continuación le siguen los argumentos de la función separados por uno o más espacios. La llamada a la función finaliza con un paréntesis de cierre. Tiene una sintaxis y semántica simples. Sólo busca relaciones entre los objetos creados, las variables y las listas, que son sus estructuras básicas. La intercambiabilidad del código y los datos también da a Lisp su instantáneamente reconocible sintaxis. Su sintaxis estaba basada en la sintaxis de ART (otra herramienta para el desarrollo de sistemas expertos).
LENGUAJES DE CUARTA GENERACIÓN
Los lenguajes de cuarta generación son ciertas herramientas prefabricadas, que aparentemente dan lugar a un lenguaje de programación de alto nivel que se parece más al idioma inglés que a un lenguaje de tercera generación, porque se aleja más del concepto de "procedimiento". Pueden acceder a bases de datos.
Algunos restringen el nombre de "lenguajes de cuarta generación" para los lenguajes orientados a objetos.
Ventajas y desventajas de los lenguajes de cuarta generación
Ventajas:
Permiten elaborar programas en menor tiempo, lo que conlleva a un aumento de la productividad.
El personal que elabora software sufre menos agotamiento, ya que generalmente requiere escribir menos.
El nivel de concentración que se requiere es menor, ya que algunas instrucciones, que le son dadas a las herramientas, a su vez, engloban secuencias de instrucciones a otro nivel dentro de la herramienta.
Cuando hay que dar mantenimiento a los programas previamente elaborados, es menos complicado por requerir menor nivel de concentración.
Desventajas:
Las herramientas prefabricadas generalmente son menos flexibles que los lenguaje de alto nivel.
Se crea dependencia de uno o varios proveedores externos, lo que se traduce en pérdida de autonomía. A menudo las herramientas prefabricadas contienen librerías de otros proveedores, que conlleva a instalar opciones adicionales que son consideradas opcionales. Los programas que se elaboran generalmente se ejecutan sólo con la herramienta que lo creó (a menos que existan acuerdos con otros proveedores).
A menudo no cumplen con estándares internacionales ISO ANSI. Por este motivo invertir tiempo y dinero es un riesgo a futuro, porque no se sabe a ciencia cierta cuanto tiempo permanecerá la herramienta y su fabricante en el mercado.

Tipos
Un número de diferentes tipos de 4GLs existir:
Tabla basada en la programación, por lo general se ejecuta con un marco de tiempo de ejecución y bibliotecas. En lugar de utilizar código, el desarrollador define su lógica mediante la selección de una operación en una lista predefinida de comandos de manipulación de la tabla de memoria o los datos. En otras palabras, en lugar de la codificación, el programador utiliza el algoritmo de programación basada en tablas. Un buen ejemplo de este tipo de lenguaje 4GL es PowerBuilder. Estos tipos de herramientas se pueden utilizar para el desarrollo de aplicaciones de negocios por lo general consiste en un paquete que permite tanto la manipulación y la presentación de datos de negocios, por lo tanto, vienen con pantallas de interfaz gráfica de usuario y editores informe. Por lo general, ofrecen integración con archivos DLL de bajo nivel generados a partir de un 3GL típica para cuando surja la necesidad de más hardware/operaciones específicas del sistema operativo.

Lenguajes de programación Informe-generadores tienen una descripción del formato de datos y el informe de generar y de que, o bien generar el informe requerido directamente o que generan un programa para generar el informe. Ver también RPG
Del mismo modo, las formas generadores gestionar las interacciones en línea con los usuarios del sistema de aplicación o generar programas para hacerlo.
Más ambicioso intento 4GLs para generar automáticamente los sistemas completos de los resultados de las herramientas CASE, las especificaciones de las pantallas e informes, y posiblemente también la especificación de una lógica de procesamiento adicional.
4GLs de gestión de datos tales como SAS, SPSS y Stata proporcionan comandos de codificación sofisticados para la manipulación de datos, la remodelación de archivo, la selección de casos y documentación de los datos en la preparación de los datos para el análisis estadístico y presentación de informes.
Algunos 4GLs tienen herramientas integradas que permiten la especificación fácil de toda la información necesaria:
La versión de James Martin de la Información Ingeniería metodología de desarrollo de sistemas fue automatizado para permitir la entrada de los resultados de análisis de sistemas y el diseño en forma de diagramas de flujo de datos, diagramas entidad relación, diagramas de entidad de la historia de vida, etc de la cual cientos de miles de líneas de COBOL serían generadas durante la noche.
Más recientemente Oracle Designer de Oracle Corporation y Oracle Developer Suite de productos 4GL podrían integrarse para producir definiciones de bases de datos y los formularios y programas de informes.
Se está produciendo una auténtica revolución en la función de Sistemas de Información. En ella intervienen un buen número de factores -políticas empresariales, carreras profesionales, capacidades de recursos humanos, misión y relaciones- y, cuando haya terminado, la profesión de sistemas de información no se parecerá en nada a los departamentos informáticos actuales.

En sus 40 años de historia, los profesionales de Sistemas de Información no se han visto afectados nunca por tantos factores diferentes como ahora. Los siguientes son algunos de ellos:
Tecnología: Internet/intranets; Java; garantizar la integridad desktop en redes complejas; integración de data warehouses; comercio electrónico; seguridad.
Recursos humanos: Los gastos para resolver el problema del año 2000; la escasez de profesionales informáticos; la necesidad de conocimientos de diseño, más que de programación, para aplicaciones multimedia e Internet; el desfase entre oferta/demanda de personal en tantas áreas, como el proceso en redes de nueva generación, SAP y data warehouse.
Económicos: El coste de las reparaciones para el problema del año 2000 y los gastos correspondientes, con el impacto consiguiente sobre los presupuestos de desarrollo e infraestructura; el continuo escalamiento de los costes de soporte técnico.
De organización: El impacto del downsizing y del outsourcing sobre la confianza, la moral y la lealtad de los profesionales informáticos; la decepción frente a las expectativas de que el
Director de Sistemas de Información debe ser un mago sobrehumano capaz por sí solo de conseguir una ventaja competitiva y satisfacer instantáneamente todas las necesidades de la empresa; el problema permanente de equilibrar la coordinación central de los recursos de Tecnologías de la Información con la utilización y la adopción de decisiones descentralizadas, que está en la raíz de las políticas corporativas de la organización informática.
Las implicaciones actuales
Individualmente, cada uno de estos factores señala la existencia de minas antipersonales e indicaciones de peligro a lo largo de la ruta evolutiva del sector de Sistemas de Información.
Y, en conjunto, eliminan cualquier ruta clara hacia el futuro. Habrá que abrirse camino por todos los medios; el sector informático no puede avanzar de manera insegura y con desvíos hacia un futuro tan complejo e incierto. Cualquiera que sea el resultado de la revolución, con seguridad dará lugar a un desplazamiento desde la tecnología a las personas. “High tech” es en realidad ahora un sinónimo de “High commodity”, es decir, de productos tecnológicos de venta y uso corriente. Cada innovación tecnológica genera su propia transformación o commoditización. La alegría al adquirir un portátil con pantalla de 14 pulgadas y 80 MB de memoria RAM se desvanece al pensar: “Sí, pero su velocidad es de sólo 166 MHz”. Lo último en 1997, está pasado de moda en 1998. El desarrollo a pequeña escala de sitios Web, Internet e intranet es hoy una actividad corriente, dos años después de ser considerada como una actividad entre las más avanzadas, gracias a los excelentes kits de software hágalo-usted-mismo que pueden adquirirse en cualquier centro comercial. Sin embargo, integrar estos componentes tipo commodity no es una actividad corriente, ni lo será durante los próximos 40 años por lo menos. La verdadera revolución se refiere a las personas.
La tecnología es actualmente algo que se compra. Con frecuencia, se están alquilando personas junto con la tecnología, a través de integradores de sistemas, firmas de consultoría y vendedores. Por ello, conviene destacar que el futuro del sector informático depende de encontrar personas no corrientes y en contratar tecnología. Esto significará una unidad de Sistemas de Información de nuevo estilo, más pequeña pero mucho más efectiva, influyente y activa, que será el origen de una ventaja organizacional en base a las Tecnologías de la Información. Su agenda de actividades incluirá la innovación, el servicio técnico y la utilización del tiempo necesario para atender a sus clientes comerciales en lugar de intentar atender simultáneamente a las demandas prácticamente imposibles a las que se enfrenta la unidad de Sistemas de Información tradicional dentro de la empresa.
En realidad, resulta prácticamente imposible determinar qué dirección exacta seguirá la revolución informática, pero la siguiente será la más probable: el éxito será para aquellas organizaciones de Sistemas de Información que desechen la idea de que la tecnología y el concepto de informática están formadas principalmente por personal a tiempo completo.
Por el contrario, estas organizaciones crearán un grupo o elite de Sistemas de Información muy reducido que estará totalmente centrado en la integración; devolverán todas las operaciones de tecnología a unidades especializadas autónomas y organizadas en torno a productos corrientes o commodities; y se organizará como asesores a los diversos grupos -unidades comerciales, equipos técnicos y empresas externas bajo contrato- que colaborarán en las decisiones relativas a tecnología.
Será necesario, por lo tanto, renunciar a la tecnología, ya que sería un hándicap para la función de Sistemas de Información dentro de esa revolución, y contratar por el contrario externamente los conocimientos y capacidades tecnológicas necesarias. Las cuales deberán ser las mejores que puedan conseguirse, ya que serán imprescindibles.
Además, habrá que identificar cuáles serán las decisiones tecnológicas a adoptar por la propia empresa para lograr los objetivos trazados. Convertirse en un experto en relación con ellas, y actuar como asesores de las personas que tendrán la responsabilidad de adoptarlas. Y crear un grupo de entre veinte y cuarenta personas que sean verdaderas estrellas en los sectores de integración de las áreas tecnológica/comercial y de las áreas de telecomunicaciones/bases de datos/equipos informáticos.
Deberá aceptarse también que la profesión informática se está transformando para convertirse en algo muy parecido a la actividad en el sector legal. Una firma de asesoría jurídica, por ejemplo, tiene un pequeño núcleo de abogados corporativos, pero muy poco “staff”. La profesión legal está formada por independientes, especialistas y firmas pequeñas y grandes a las que recurren las empresas a través de su propio grupo básico interno. De esta forma es como se estructurará la función de Sistemas de Información dentro de las empresas a medio plazo: independientes, especialistas y firmas externas bajo contrato.
INFOGRAFÍA
INTELIGENCIA ARTIFICIAL
Comentarios
Publicar un comentario